Data Normalization Explained: 1NF, 2NF, 3NF With Examples

Poorly structured databases cause real problems: redundant records, update errors, and queries that slow to a crawl as tables grow. Data normalization explained at its core is the process of organizing a relational database to reduce redundancy and protect data integrity. It's one of the most foundational concepts in database design, and getting it right affects everything downstream, from application performance to long-term data reliability.
Whether you're building a healthcare application that pulls patient records from multiple EHR systems or designing a SaaS product from scratch, normalization determines how cleanly your data behaves at scale. At SoFaaS, we work with this reality daily: our platform routes clinical data between third-party applications and EHR systems like Epic and Cerner, where consistent, well-structured data isn't optional, it's a requirement for accurate patient care and regulatory compliance.
This guide walks through the three most common normal forms, 1NF, 2NF, and 3NF, with concrete examples showing how to apply each one. By the end, you'll understand not just what each normal form requires but why it matters and how to spot violations in your own database schemas before they become costly technical debt.
Why normalization matters in real databases
When you skip normalization, small problems compound quickly. A single redundant column in a table with a million rows doesn't just waste storage - it creates a maintenance burden that grows every time your application writes new data. The principles behind data normalization explained properly show you that structure decisions made early in a project determine whether your database stays manageable or becomes a serious liability down the road.
The hidden cost of redundant data
Redundancy sounds harmless until you need to update a value stored in 50,000 rows instead of one. Imagine a table that stores a customer's city alongside every order they've ever placed. If that customer moves, every order row needs updating - and if even one row gets missed, your reports will return contradictory results. This type of problem is called an update anomaly, and it's one of the most common sources of silent data corruption in production systems.
Redundant data also inflates storage requirements unnecessarily. More critically, it creates query complexity - joins become harder to reason about when the same fact lives in multiple places, and aggregations return wrong results when duplicate rows get counted more than once. The longer redundancy persists in a schema, the more code gets written around it, making the underlying design problem harder and more expensive to fix.
Fixing a redundant schema after millions of rows have been written is significantly more costly than normalizing it before the first record is inserted.
Insertion, deletion, and update anomalies
Three specific failure patterns emerge when a schema lacks normalization: insertion anomalies, deletion anomalies, and update anomalies. An insertion anomaly happens when you can't add a new record without also supplying unrelated data. For example, if your table links products to suppliers but requires a product to exist before you can record a supplier, you have no clean way to store a supplier who hasn't yet provided any products.
A deletion anomaly is the inverse: removing one record unintentionally destroys other facts. If deleting the last order from a supplier also removes your only record of that supplier's contact information, your schema forces you to lose data you actually need. Both of these problems trace back to storing unrelated facts in the same table rather than separating them into purpose-built structures.
Update anomalies tie it all together. When the same fact is stored in multiple rows, a partial update leaves your data in an inconsistent state. Normalized tables prevent this by ensuring each fact has exactly one authoritative location, making updates precise and reliable regardless of table size.
Why this matters more in healthcare data
Healthcare applications face these risks at a heightened level because data accuracy directly affects patient outcomes. A medication listed in two places with conflicting dosages isn't just a database problem - it's a clinical risk. Platforms like SoFaaS handle data flowing between EHR systems and third-party applications, where inconsistencies at the schema level can propagate through integrations and surface as incorrect information in clinical workflows. Normalization is part of the foundation that makes reliable, high-stakes data exchange possible in the first place.
Core concepts: keys, relationships, dependencies
Before you can normalize a table, you need to understand the building blocks that normalization operates on. Three concepts sit at the center of every normalization decision: keys, relationships between tables, and functional dependencies. Getting these right is what makes data normalization explained in any meaningful way - you can't reason about removing redundancy without first understanding what holds your data together and how one column's value relates to another.
Primary keys and foreign keys
A primary key is a column, or a combination of columns, that uniquely identifies each row in a table. No two rows can share the same primary key value, and it can never be null. When a primary key from one table appears in another table to link the two, it becomes a foreign key. Foreign keys define the relationships between tables - the mechanism that lets you split data across multiple tables without losing the connections between related records.
Choosing the right primary key early in your schema design prevents a range of normalization problems before they start.
Your choice of primary key also determines what counts as a duplicate in your data. A natural key uses real-world attributes like an email address or a government-issued ID number. A surrogate key is an artificial identifier, like an auto-incrementing integer or UUID, created solely to serve as a unique row identifier. Surrogate keys are generally more stable because real-world attribute values change, while an internal system identifier does not.
Functional dependencies
A functional dependency exists when one column's value determines another column's value. If knowing a CustomerID always tells you that customer's name, the name is functionally dependent on the ID, written as: CustomerID → CustomerName. Recognizing these dependencies is what lets you spot when unrelated facts are bundled into the same table, which is exactly the condition normalization corrects.
Partial and transitive dependencies are two specific types that become central in 2NF and 3NF respectively. A partial dependency means a non-key column depends on only part of a composite primary key rather than the whole key. A transitive dependency means a non-key column depends on another non-key column instead of the primary key directly. Both patterns are clear signals that your schema needs restructuring.
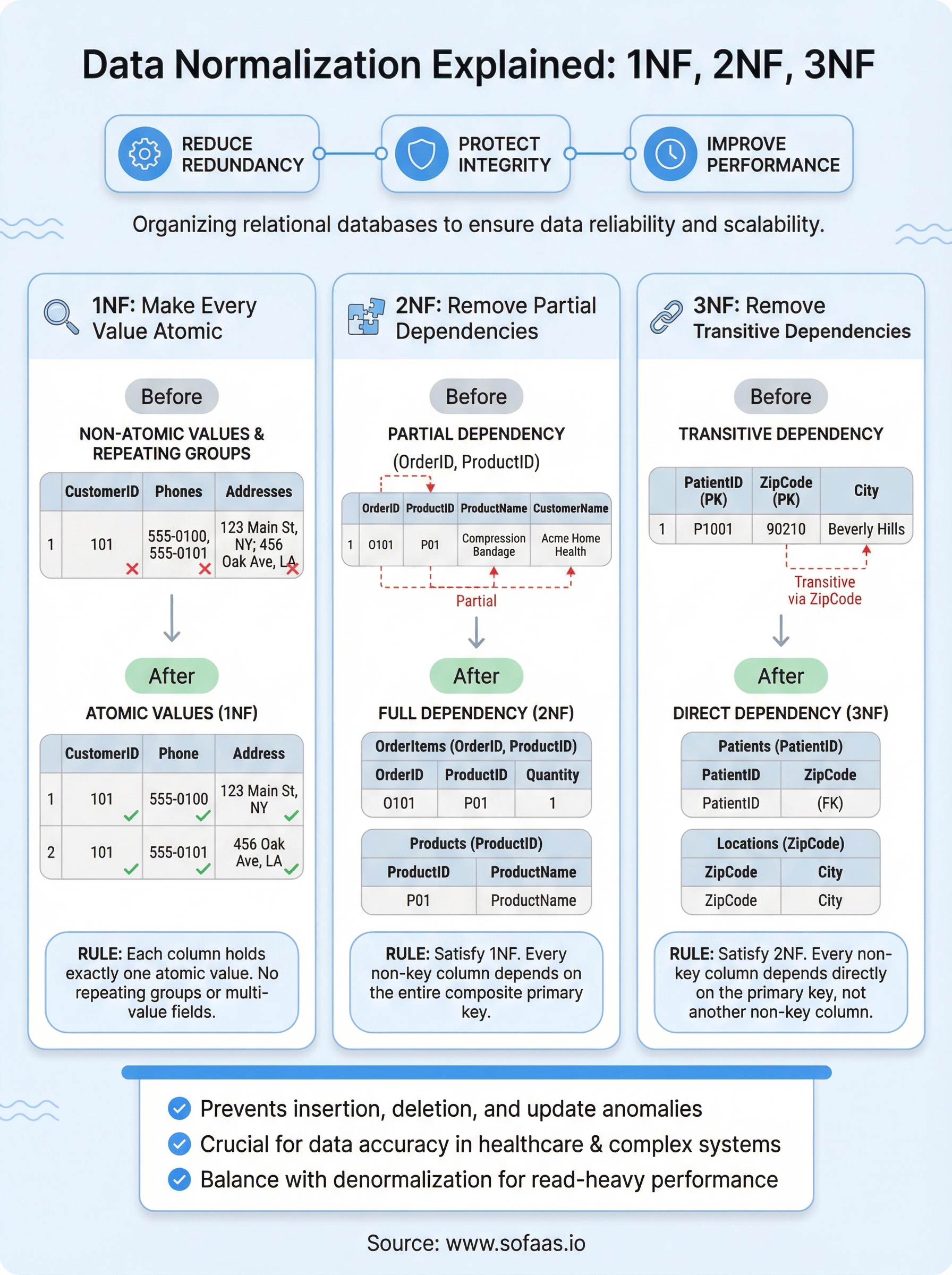
First normal form: make every value atomic
First Normal Form, or 1NF, is the starting point for any normalization effort. A table satisfies 1NF when every column holds exactly one value per row, all values in a column share the same data type, and each row is uniquely identifiable. When data normalization explained at this level, 1NF is less about complex theory and more about enforcing discipline in how you store individual facts.
What atomic values actually mean
An atomic value is one that cannot be meaningfully broken down further within your data model. A column storing a single city name is atomic. A column storing "New York, Los Angeles, Chicago" as a comma-separated string is not. That multi-value field forces your application code to parse the column every time you query it, and it makes filtering or indexing on individual values extremely difficult.
Storing multiple values in a single column shifts the data's complexity out of the database and into your application layer, where it becomes much harder to control.
The same problem appears when developers create repeating column groups instead of using separate rows. For example, adding Phone1, Phone2, and Phone3 as separate columns in a customer table violates 1NF because you're implying a repeating structure within the row itself. If a customer gets a fourth phone number, your schema breaks without an ALTER TABLE statement.
Repeating groups and how to fix them
The fix for both multi-value fields and repeating column groups follows the same pattern: move the repeating data into its own table and use a foreign key to link it back to the parent record. Instead of storing multiple phone numbers in the customer row, you create a CustomerPhones table with CustomerID and PhoneNumber columns. Each phone number gets its own row, your schema stays clean, and adding a new number never requires a structural change.
This separation also makes queries significantly cleaner. Filtering customers by a specific phone number becomes a straightforward join rather than a string-parsing operation, and indexing works properly because each value occupies its own row. Getting 1NF right sets a stable foundation for applying 2NF and 3NF without introducing new structural problems along the way.
Second normal form: remove partial dependencies
Second Normal Form, or 2NF, builds directly on 1NF by addressing a specific structural problem: partial dependencies. A table is in 2NF when it already satisfies 1NF and every non-key column depends on the entire primary key, not just a portion of it. This rule only applies to tables with composite primary keys (keys made up of two or more columns), since a single-column key can't be partially depended upon by definition.
What a partial dependency looks like
Partial dependencies are easiest to spot with a concrete example. Imagine an OrderItems table that uses a composite primary key of (OrderID, ProductID) and also stores ProductName and CustomerName alongside the order quantity.

| OrderID | ProductID | ProductName | CustomerName | Quantity |
|---|---|---|---|---|
| 101 | P01 | Compression Bandage | Acme Home Health | 10 |
| 101 | P02 | Pulse Oximeter | Acme Home Health | 3 |
| 102 | P01 | Compression Bandage | Valley DME | 5 |
ProductName depends only on ProductID, not on the full (OrderID, ProductID) key. CustomerName depends only on OrderID. Both columns are partially dependent, which means the same product name appears in every row that references that product. If the name changes, you have to update every matching row or accept inconsistent data across your tables.
A partial dependency is a sign that your table is trying to describe more than one subject at the same time.
How to restructure for 2NF
The fix requires you to decompose the table into separate tables, each focused on a single subject. In this case, you move ProductName into a Products table keyed by ProductID and move CustomerName into an Orders table keyed by OrderID. Your OrderItems table then holds only OrderID, ProductID, and Quantity, which are the columns that genuinely depend on the full composite key.
With data normalization explained at this level, the benefit becomes clear: each fact now lives in exactly one place. Updating a product name means changing one row in one table, and that change propagates automatically through any query that joins the tables together. Your schema becomes easier to maintain, and the risk of update anomalies drops significantly.
Third normal form and when to denormalize
Third Normal Form, or 3NF, extends 2NF by targeting a different category of structural problem: transitive dependencies. A table satisfies 3NF when it already meets 2NF requirements and every non-key column depends directly on the primary key, not on another non-key column. With data normalization explained through this lens, 3NF ensures each column in your table describes the subject identified by the primary key and nothing else.
What transitive dependencies look like
A transitive dependency occurs when one non-key column determines the value of another non-key column, creating an indirect relationship to the primary key. Consider a Patients table where PatientID is the primary key, and the table also stores ZipCode and City. PatientID determines ZipCode, and ZipCode determines City. That makes City transitively dependent on PatientID through ZipCode rather than directly, which means you're storing city information in a patients table when it actually belongs to the zip code.

A transitive dependency is a signal that two different facts are sharing a table when each fact belongs in its own dedicated structure.
The fix follows the same decomposition pattern you applied in 2NF. You move ZipCode and City into a separate Locations table keyed by ZipCode, then reference it from the Patients table using a foreign key. Each table now describes exactly one subject, and updating a city name for a given zip code requires changing one row in one place rather than every patient record associated with that area.
When denormalization makes sense
Strict 3NF isn't always the right endpoint for a production schema. Read-heavy systems, particularly reporting databases and data warehouses, sometimes benefit from intentional denormalization where you trade some redundancy for faster query performance. Joining five normalized tables on every dashboard load adds latency that users feel, and in those contexts, a pre-joined or flattened table can reduce query complexity without sacrificing data integrity at the source.
The key is treating denormalization as a deliberate, documented choice rather than an accident. You should keep your normalized tables as the authoritative source of truth and build denormalized structures on top of them, typically through materialized views or scheduled jobs, so any redundancy stays controlled and any updates remain predictable.
A quick workflow for normalizing a schema
Having data normalization explained across 1NF, 2NF, and 3NF gives you the theory, but applying it to a real schema requires a repeatable process. The steps below give you a practical order of operations you can follow whether you're designing a new database from scratch or cleaning up an existing one that has accumulated structural problems over time.
Audit your tables and catalog every fact
Start by listing every table in your schema and writing down, in plain language, what subject each table is supposed to describe. This single exercise often reveals the core problem immediately. If you find yourself writing "this table stores orders and also customer addresses and also product pricing," you already know decomposition is coming. Every table should describe exactly one subject, and every column in that table should be a fact about that specific subject and nothing else.
After cataloging subjects, go column by column and ask: what does this column describe? If a column describes something other than the table's primary subject, flag it for migration. This inventory becomes your working blueprint for restructuring the schema before you write a single line of migration code.
Documenting what each table is supposed to represent before you start restructuring it saves you from solving the wrong problem.
Apply normal forms in sequence and validate each step
Once your audit is complete, work through the normal forms in order rather than trying to jump straight to 3NF. First, confirm every column holds atomic values and no repeating groups exist. Fix any violations by splitting multi-value fields into separate rows in a dedicated table. Second, check for partial dependencies by identifying every composite primary key and confirming that each non-key column depends on the full key. Decompose any table where that condition fails. Third, scan for transitive dependencies by asking whether any non-key column determines another non-key column, and move those relationships into their own tables.
After each step, run your existing queries against the restructured schema and confirm they still return correct results. Validation at each stage catches problems introduced by decomposition early, before they compound into larger issues that affect application behavior.
Key takeaways
With data normalization explained across 1NF, 2NF, and 3NF, you now have a clear framework for structuring relational databases that stay accurate and maintainable as they grow. Each normal form targets a specific problem: 1NF eliminates multi-value fields, 2NF removes partial dependencies on composite keys, and 3NF cuts transitive dependencies so every non-key column answers directly to the primary key. Applied in sequence, these three steps prevent the insertion, deletion, and update anomalies that corrupt data silently over time.
Reliable data structure matters even more when your application exchanges clinical or operational records across integrated systems. If you're building a healthcare application that needs consistent, well-structured data flowing between your product and major EHR systems like Epic or Cerner, your integration layer needs to handle that complexity without adding new risk. Connect your healthcare app to EHRs in days and keep your focus on building, not on managing infrastructure.
The Future of Patient Logistics
Exploring the future of all things related to patient logistics, technology and how AI is going to re-shape the way we deliver care.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.